고정 헤더 영역
상세 컨텐츠
본문
0. CNN (Convolutional Neural Network)
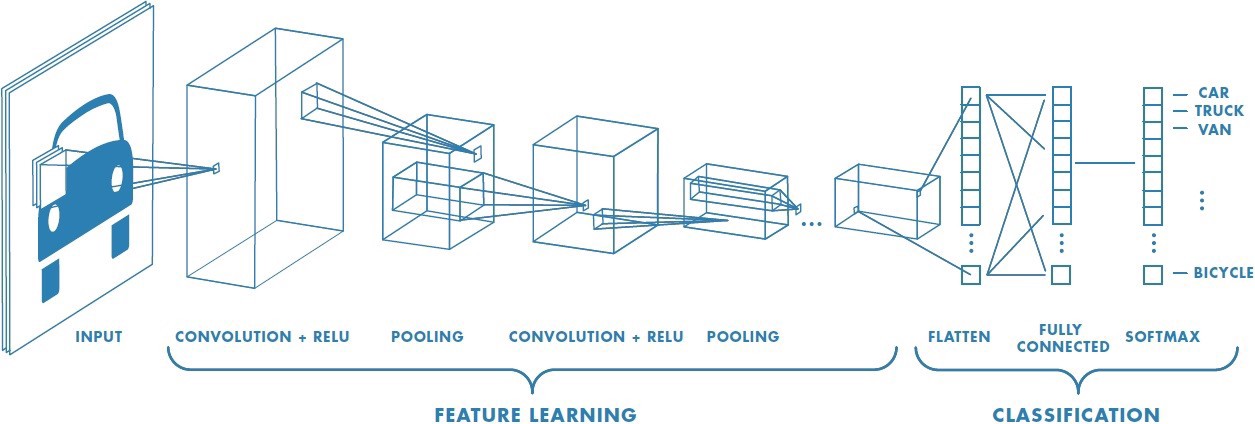
CNN은 이미지 데이터의 특성을 잘 반영할 수 있는 인공신경망 모델로 convolution(합성곱)을 통한 feature learning 과정을 거친 뒤 신경망을 통해 분류를 진행한다. Convolution 연산 - Activation 연산 - Pooling 연산의 반복으로 구성된다.
▷ Feature Learning
1) Image Convolution
행렬로 이루어진 필터가 일정 간격(stride)만큼 입력데이터를 훑고 지나가면서 행렬곱을 진행한다. 필터를 통해 함축된 결과값은 기존 이미지 데이터를 함축적으로 설명한다고 볼 수 있다. (수없이 많은 feature들로 이루어진 데이터에서 에센스를 빼내는게 주목적이다)
필터 안에 있는 값은 일종의 파라미터로써 인공신경망에서처럼 역전파를 통해 추정을 한다.

2) Activation
비선형 변환을 진행한다
3) Paddling
필터의 방문 빈도수가 적은 가장자리에 위치한 값들을 보장하기 위해 전체 입력 데이터 행렬 주위에 0을 감싼다

4) Pooling
Feature map의 공간적 크기를 줄이기 위해 해당 필터에서 구역을 나누어 그 구역의 최대값(Max Pooling) 혹은 평균값(Average Pooling) 으로 일정 영역의 정보를 축약한다

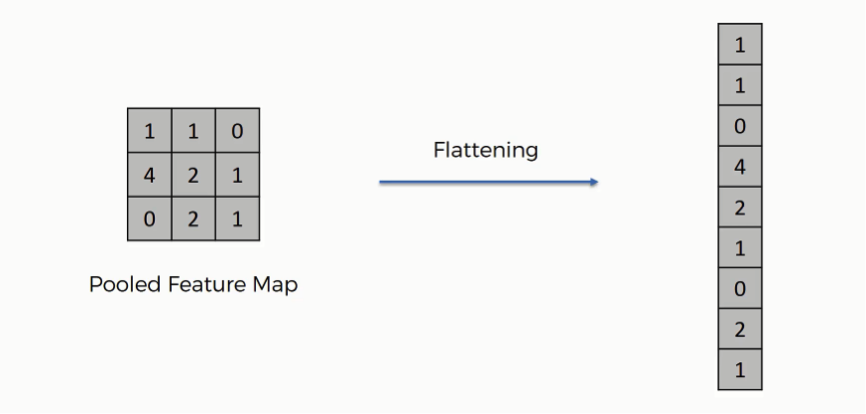
5) Flattening
2차원 혹은 3차원이었던 행렬/텐서 구조를 최종적으로 1차원 벡터로 변환시키게 되었고 이를 인공신경망에 넘겨준다
▷Classification

1. Introduction
머신 러닝을 통해 실제 존재하는 물체를 인지하기 위해서는 수많은 이미지 사진들을 모델에 주입시켜야 한다. 그렇게 수많은 데이터를 단순 뉴럴 네트워크로 구성했을 때보다 CNN을 통해 학습 시키게 되면 더 적은 연관성과 파라미터들로 더 쉽게 학습시킬 수 있다는 장점이 있다. 따라서 해당 논문에서는 5개의 convolutional 층과 3개의 fully-connected 층으로 구성된 모델을 제안한다.
2. The Dataset
해당 모델을 구축하는데 있어 사용한 데이터는 ImageNet으로 22,000개의 카테고리로 분류된 1500만 개의 사진 데이터이다. 256 x 256 해상도로 이루어져 있으며 RGB 3개의 픽셀로 구성되어 있다. ILSVRC-2012에서 우수한 성적을 거두었다.
*ILSVRC (ImageNet Large-Scale Visual Recognition Challenge)
ImageNet 이미지를 인식하여 정확도를 겨루는 대표적인 시각지능 대회. 2012년 발표된 Alexnet을 기점으로 해당 대회에서 우수한 성능을 보인 모델들이 향후 CNN과 딥러닝 연구 발전에 큰 기여를 함.

3. The Architecture
- Relu Nonlinearity
뉴럴네트워크 모델에서 활성화함수(activation function)란 노드에 입력된 값들을 조합하는 함수를 일컫는다. 이때 기본적으로 시그모이드 함수를 사용하곤 하는데 그렇게 되면 기울기 소실(gradient vanishing) 현상이 발생하게 된다.
(뉴럴 네트워크는 역전파 알고리즘을 통해 파라미터를 추정하게 되는데 시그모이드 함수와 같이 매우 복잡하게 비선형적으로 얽혀있는 함수를 이용하게 되면 파라미터를 추정하는 과정에 있어서 문제가 발생한다.)
따라서 해당 모델에서는 활성화 함수로 Relu를 사용하였고 더 빠른 학습을 진행할 수 있었다.


- Local Response Normalization
Relu 함수는 입력값에 대해서 추가적인 정규화(normalization) 과정이 필요없다는 장점이 있다. 해당 논문에서는 추가적으로 local normalization이라는 작업을 언급하는데 아래와 같은 수식을 통해 인접한 위치에 있는 값들에 따라 kernel map을 정렬하는 과정이라고 설명하고 있다.
양수값을 선형적으로 그대로 뱉어내는 Relu 함수에 의해 큰 값들에 의해 크기가 작은 값들이 묻혀지는 현상이, 특정인간의 뉴런에서 한 영역에 있는 신경세포가 상호 간 연결된 이웃 신경 세포를 컨트롤 하려는 과정으로 표현된 것이라고 보면 된다. (이를 측면 억제 lateral inhibitaion이라고 한다) 해당 작업을 통해 오차율을 더 줄일 수 있었다고 한다.



- 전반적인 진행방향

4. Reducing Overfitting
① Data Augmentation
데이터 증폭을 위해 256 x 256 사이즈 이미지로부터 랜덤으로 224 x 224 형태를 추출하여 데이터의 factor(논문에 나온 그림을 보았을 때 convolution layer에서 fc layer로 넘어갈때 노드의 개수를 의미하는 것 같다)를 2048개로 늘리는 작업을 진행하였다. 또한 PCA를 통해 RGB성분을 추출하여 각각의 RGB강도를 다르게 하여 데이터를 증폭하는 과정도 거쳤다.


② Dropout
은닉층에 있는 노드들에 0.5의 확률로 입력값이 0이 되도록 설정한다. 즉 학습 과정에서 일부러 특정 노드들에 연결된 가중치들은 업데이트를 하지 않도록 무작위로 입력값을 꺼버린다. 뉴런이 다른 뉴런에 의존하는 상황을 방지하게 되면서 매번 다른 모형, robust한 속성들을 만들어낼 수 있다. 논문에서는 첫번째, 두번째 fc 층에 dropout을 적용하였다.

5. Details of learning
파라미터 업데이트 과정에서 적용한 수식은 아래와 같다.

확률적 경사하강법(Stochastic gradient descent)를 통해 128개의 배치 사이즈, 0.9의 모멘텀, 0.0005의 weight decay를 적용하였다.
(weight decay란 과적합 완화를 위해 오차함수에 가중치 제곱합을 더하는 과정을 말한다)
(momentum이란 경사 하강법의 수렴 성능을 향상 시키기 위한 방법으로 기울기를 찾아내기 위한 방향의 indicatior 같은 느낌)
※ Remind -> 경사하강법을 통한 파라미터 업데이트

6. Result

'심화 스터디 > 분류 예측' 카테고리의 다른 글
| [분류 예측 스터디] Faster R-CNN - Towards Real-Time Object Detection with Region Proposal Networks (0) | 2022.05.29 |
|---|---|
| [분류 예측 스터디] 핸즈온 9장 비지도 학습 (0) | 2022.05.29 |
| [분류 예측 스터디] 핸즈온 8장 차원축소 (0) | 2022.05.12 |
| [분류/예측 스터디] BERT (0) | 2022.05.12 |
| [분류 예측 스터디] A Tutorial on Principal Component Analysis (0) | 2022.05.11 |





댓글 영역