[강화학습 스터디] Network Randomization: A Simple Technique for Generalization in Deep Reinforcement Learning(ICLR 2020)
기존 Deep RL의 agents는 unseen environment에 대한 generalization이 부족했다. 아래의 사진과 같이 2D CoinRun, 3D DeepMin Lab, 3D Surreal robotics 등에서 학습 때 사용되었던 object, background, floor와 test할 때 다를 경우 성능이 크게 감소한다.

여러 Generalization 방법
Regularization: L2 norm, Dropout, BatchNorm
Data Augmentation: cutout, grayout, inversion, color jitter
- cutout: 임의의 크기, 생상의 box를 random number만큼 만드는 방법
- grayout: RGB 3개 channel을 평균으로 하는 방법
- inversion: 픽셀 값을 50% 확률로 반전
- color jitter: brightness, contrast 등을 변화
Random Neural Network
s: original input, clean input
f: radnom network
ø: random network의 파라미터
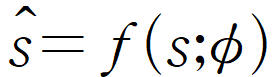

Random Network를 넣어 RL agent에게 변형된 input observation을 넣어준다. 이때 Random neural network는 input observation의 dimension의 변화를 피하기 위해 single Convolution Neural Network를 이용한다.
CNN의 re-initialize(randomize) weight을 통해 input observation의 전체 structure는 유지하면서 color와 같은 부분의 randomize가 진행되어 random NN는 environments with different visual patterns를 생성한다.

randomized input observation을 이용하여 RL agents를 학습시킨다.

이런 randomized environment를 통해 agent는 robost, invariant representation을 학습할 수 있게 된다.
CNN의 특징
CNN은 shape보다는 texture와 color에 bias하다는 특징을 가지고 있다. 해당 논문에서는 이를 설명하기 위해 Kaggle의 유명한 데이터인 "Cats vs Dogs" 데이터를 이용하여 실험을 진행했다. 일부러 training data에는 Cat은 검은 계열만, Dog는 흰 계열만 모아놓았고 반대로 test data에는 Cat은 흰색만 Dog는 검은색만 모아놓았다.

image processing에 사용되는 여러 방법들 grayout(GR), cutout(CO), inversion(IV), color jitter(CJ)를 사용한 방법과 논문에서 설명하는 randomize CNN을 사용했을 때의 성능을 비교해보았다.
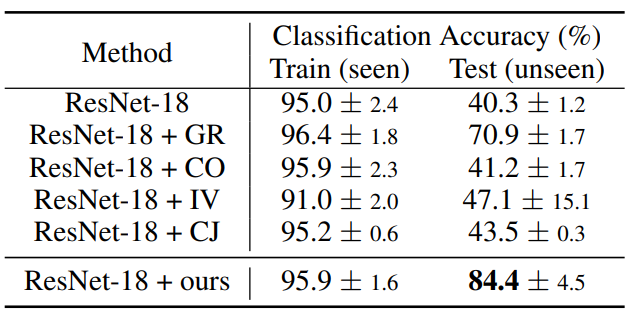
DNN인 ResNet-18의 test accuracy가 떨어지는 것을 통해 overfitting이 발생된 것을 알 수 있다. 이를 해결하기 위해 앞에서 언급한 여러 방법론과 비교를 진행했다. 논문에서 제안하는 방법이 다른 방법론들보다 성능이 높은 것을 통해 해당 방법론이 semantic information을 유지하면서 visual appearance를 바꿔줌으로써 shape과 같은 의미있는 information을 capture하는데 도움을 준다는 것을 알 수 있다.
Feature matching loss
original observation과 randomized observation의 latent feature 사이의 거리

feature matching loss를 optimize함으로써 policy network가 더 robust, invarinace representation을 학습할 수 있게 된다.
Experiments
PPO
DO: dropout
L2: L2 regularization
BN: batch normalization
CO: cutout(augmentation method)
GR: grayout(augmentation method)
IV: inversion(augmentation method)
CJ: color jitter(augmentation method)
oracle: upper bound, agent를 unseen environment에서 train시킨 upper bound
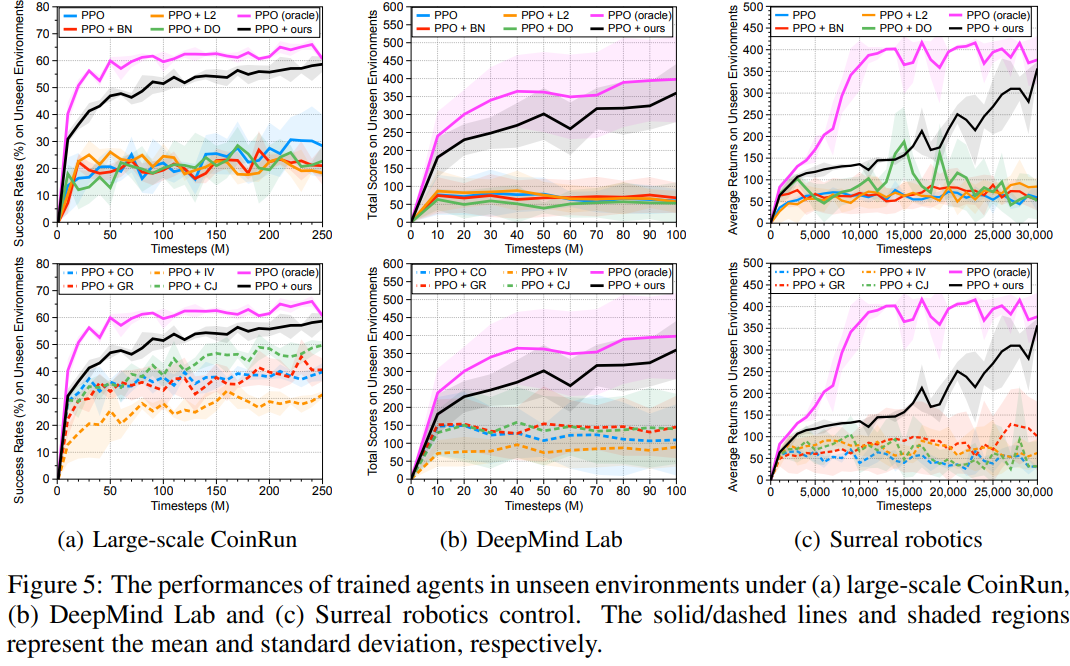
CoinRun과 DeepMin Lab, Surreal robotics에서 모두 논문에서 제시하는 방법론의 성능이 가장 oracle과 근접한 높은 성능을 보이는 것을 알 수 있다.