[분류/예측 스터디] BERT
작성자 : 채윤병
2019년 5월에 Google 에서 발표한 자연어 모델
BERT(Bidirectional Encoder Representations from Transformers) - 트랜스포머의 attention mechanism을 양방향에서 가능하도록 한 모델
1. Introduction
자연어 처리 모델에서 pre-trained된 모델을 특정 task로 적용하는 데의 2가지 전략
1. Feature-based 2. Fine-tuning
BERT가 나오기 전, 기존 모델들의 한계점 : 방향이 unidirectional 해서 pre-training 과정에서 선택지를 제한한다.
OpenAI의 GPT의 경우 한쪽 방향만 고려해 attention을 진행

BERT가 unidirectional한 constraint를 어떻게 완화했을까? - Masking!(masked language model, MLM)
Input 토큰(=단어) 중 랜덤하게 masking을 진행하고 pre-training의 목적은 문맥(context)를 통해서 masked token을 예측하는 것 (문맥을 고려할 때 양방향을 모두 고려하기 때문에 bidirectional, random으로 masking 되는 비율은 15%)
ex) my dog is hairy 라는 문장이 input으로 들어가는 상황
80% my dog is hairy -> my dog is [mask] -> masking되는 input의 15% 중 80%는 mask 토큰으로 대체
10% my dog is hairy -> my dog is apple -> masking되는 input의 15% 중 10%는 랜덤한 다른 단어로 대체
10% my dog is hairy -> my dog is hairy -> masking되는 input의 15% 중 10%는 바꾸지 않고 진행
* 원래 단어에 편향을 주기 위함.
무조건 masking을 하는 방식이 아니라 masking으로 선택된 토큰 중에서도 확률적으로 다른 과정들이 진행된다.
-> 이 방식의 장점은 Transformer encoder는 어떤 단어들을 물어볼지, 혹은 어떤 단어들이 다른 단어로 바뀔지 모르기 때문에 이 방법을 통해 문맥적 표현을 효과적으로 학습시킬 수 있다.


2. BERT
BERT의 전체적인 과정 - pre-training -> fine tuning, 두 과정에서의 모델 구조는 같지만 pre-training과정에서만 masking이 진행된다.
Pre-training - Unlabeled data를 가지고 무작위로 masking된 masked 토큰들을 예측하며 학습이 진행.
Fine-tuning - Labeled data를 가지고 specific한 task에 대해서 학습이 진행.
Fine tuning 과정에서는 Pre-trained 된 파라미터가 Initialize되고 특정 task에 대해서 fine-tuned 된다.
특별한 토큰 [CLS] - 문장 시작을 의미, [SEP] - 문장 사이

BERT의 장점 - 다른 task에 대해서 통일된 모델 구조(Multi-layer Bidirectional Transformer)를 가지고 있다.
BERT base의 경우 - Layer = 12, Hidden size = 768, Attention head = 12
BERT large의 경우 - Layer = 24, Hidden size = 1024, Attention head = 16
BERT의 input으로는 하나의 문장 또는 2개의 문장이 들어갈 수 있음 -> sequence라고 부른다.
Pre-trained 된 BERT 모델은 Question answering이나 Language inference와 같은 task를 위해 뒤에 output layer 하나를 각각의 task에 맞게 추가하면 이용할 수 있다.
Pre-training
Pre-training 과정에서의 Unsupervised task
1. Masked LM(위에서 설명)
2. Next sentence prediction(NSP)
QA(Question answering), NLI(Natural Language Inference)와 같은 task는 두 문장간의 관계를 파악하는데 기반.
A문장과 B문장을 넣는다고 가정할 때, pre-training에서 50%는 실제로 A문장 다음에 B문장이 오고, 50%는 무작위로 다른 문장이 다음에 오게 한다.

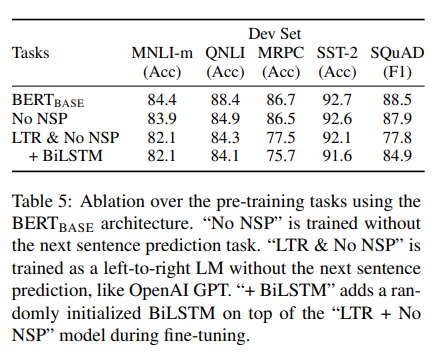
NSP(Next sentence prediction)를 Pre-training과정에서 진행한 BERT의 성능이 나머지 결과보다 더 좋았다. No NSP는 masking은 진행하되, NSP를 진행하지 않은 것이며, LTR은 한쪽 방향만을 고려한(unidirectional) left to right을 의미한다.
Fine-tuning
Transformer의 self-attention mechanism이 BERT가 다양한 task에 적용 가능하도록 한다.
두 문장일 경우
(1) Paraphrasing 관계, (2) Hypothesis-premise, (3) Question-answer, (4) Text classification, sequence tagging
* 4번의 경우 텍스트의 pair를 비활성화 시킨다.
전체 과정

Attention
Multi-head attention - Models context
Feed Forward layers - 비선형적 특성 계산
Layer norm and residuals - 정규화
Positional embeddings - 상대적인 position 학습



* 어텐션에 대한 자세항 사항 - Attention Is All You Need(논문)
유튜브 나동빈 transformer 논문 리뷰


3. Result
- 거의 모든 Task에 대해서 BERT가 좋은 성능을 보였으며 더 많은 layer로 학습 시킨 BERT-large가 가장 좋은 성능을 보였다.
- 대체적으로 모델이 크면 클수록 더 좋은 성능을 보였고 큰 task 뿐만 아니라(기계 번역) 작은 task(단순 분류)에서도 BERT가 좋은 성능을 보였다.

참조
1. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2. Attention is all you need
3. 유튜브 나동빈 transformer 논문 리뷰