[Practical Statistics for Data Scientists] B팀: Tree Models
Tree Model 개요
Tree Mode1은 CART(Classification and Regression Trees)라고도 한다. 1984년에 Leo Breiman이란 분께서 만드신 알고리즘이라고 한다. 겉으로 보기에는 매우 간단한 알고리즘 같지만, Bagging이랑 Boosting이라는 파워풀한 알고리즘들의 밑거름이 되는 기본 모델이다. Tree Model은 regression, classification에서 모두 활용될 수 있다는 장점이 있다.
그렇다면 Tree model은 무엇인가?
Tree model은 “if-then-else”룰을 따르면서 분류/예측 결과를 세분화하는 알고리즘이다. Tree model을 사용하면 데이터 내에 숨은 규칙을 용이하게 찾을 수 있고, 해석이 용이한 알고리즘을 만들 수 있다. 이런 Tree model을 “decision tree”라고도 한다.
Practical Statistics for Data Scientists에 나오는 간단한 예제를 살펴보자. 아래는 채무 이행 여부를 분류하는 tree model의 알고리즘이다. 꽤나 직관적임을 확인할 수 있다. 가장 윗부분(root)부터 “if-then-else” 분류가 시작되며 아랫부분(leaf)에서 최종 분류가 이루어짐을 확인할 수 있다. 실제로 borrower_score이 0.6 이상이고 payment_inc_ratio가 8.0인 데이터가 tree model에 들어갔을 때, 순서에 따라 채무이행을 했다고 분류할 것이다.

Recursive Partitioning Algorithm
Decision Tree 모델은, recursive partitioning을 통하여 형성된다. Recursive partitioning 알고리즘은 매우 직관적이다.
J개의 변수가 있으면
1) X1,…,Xj 각 변수마다 데이터들을 잘 분류할 수 있는 최적의 구분 구간을 찾는다.
2) 분류했던 X1,…,Xj 구분 구간 중 데이터들을 가장 잘 분류하는 구분 구간 하나를 뽑는다. 이것이 바로 첫 번째 구분 구간(root)이다.
3) 나누어진 n개의 구간들에 다시 1,2 번을 반복하여 구분 구간을 생성한다.
4) 충분하게 분류를 진행할 때까지 구분 구간을 반복생성한다.
Measuring Homogeneity or Impurity
Recursive Partitioning Algorithm의 1)에서 최적의 구분구간을 찾는 방법은 다음과 같다.
Regression에서는 주로 구분 구간에 대한 RMSE를 구하여, 가장 낮은 RMSE가나오는 구분 구간으로 분류를 진행한다.
Classification에서는 Accuracy 보다는 Impurity Score을 사용한다. Impurity(불순도) Score은 예측을 얼마나 못하였는지에 대한 지표이며, 0(완벽하게 분류)과 0.5(랜덤하게 분류) 사이의 값을 가지고 있다. 즉, 낮은 impurity를 가진 구분 구간으로 분류를 진행해야 한다.
Impurity score을 측정하는 방법은 크게 2가지가 있다.
1. Gini Impurity
이진분류를 가정했을 때, Gini Impurity의 식은 아래와 같다.

2. Entropy
이진분류를 가정했을 때, entropy의 식은 아래와 같다.
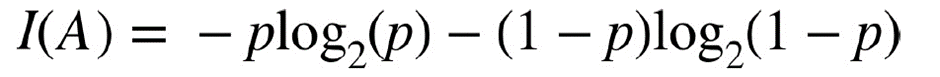
실제로 그래프를 그렸을 때, gini impurity와 entropy에서 나온 값들이 유사함을 확인할 수 있는데, entropy가 높은 accuracy rate에서 impurity score이 조금 더 높은 경향이 있다.
*p는 오분류된 데이터의 비율
Pruning
Tree Model이 커질수록 더욱 세분화된 분류를 진행하고, 그 깊이가 깊어지면 모든 데이터를 완벽히 분류하는 알고리즘을 만들 수 있다. 그러나 이는 overfitting 문제를 초래할 수 있다. 그렇기 때문에 bias-variance tradeoff를 가장 만족시키는 모델을 생성해야 한다. 이 때 사용되는 방법이 pruning인데, 나무의 가지를 친다… 라고 생각하면 이해가 편할 것 같다!
Pruning을 하는 방법들은 다음과 같다. (R 기준)
1. Minsplit, Minbucket 값 조정: Minsplit은 더욱 잘게 분류하기 위해서 마지막 leaf에 필요한 최소한의 데이터 개수이며, minbucket은 마지막 leaf에서 필요로 하는 최소한의 데이터 개수이다. 보통 minbucket = minsplit/3 의 규칙을 따른다고 한다.
2. Cp값 조정: Cp값은 Tree model의 복잡도를 나타내는 수치이며, tree model이 더욱 세분화된 분류를 진행했을 때, Cp값이 일정값 이상 높아지지 않는다면 분류를 멈춘다. Cp값이 너무 작으면 tree에서 overfitting이 발생할 것이며, 높으면 underfitting이 발생할 것이다. Cross Validation을 활용하면 최적의 Cp값을 구할 수 있다.
Tree Model의 활용
1. Tree Model은 시각화가 용이하기 때문에 데이터의 구조를 파악하기 쉽다. 어떤 변수들이 서로 연관되었는지 확인할 수 있을 뿐만 아니라 비선형적인 관계 또한 파악할 수 있다.
2. 비전문가에게 Tree Model을 설명하기가 용이하여, 모델을 판매할 때 많은 도움을 준다.