고정 헤더 영역
상세 컨텐츠
본문 제목
[Practical Statistics for Data Scientists]B팀: Evaluating Classification Models
본문
1. Accuracy
- 올바르게 예측된 비율
- $\frac{\sum True Positive + \sum True Negative}{SampleSize}$
2. Confusion Matrix
- 올바르게 또는 올바르지 않게 예측된 response의 수를 보여주는 테이블
- 보통 열은 예측 결과, 행은 true 값 사용

- 따라서 대각열은 올바르게 예측된 수를 나타내고 비대각열은 올바르지 않게 예측된 수를 나타냄
- FN: Type I error / FP: Type II error
3. The Rare Class Problem
예측할 클래스가 불균형할 경우 적은 클래스를 어떻게 잘 분류할 것인가?
ex. 만약 웹 브라우저에 방문한 소비자 중 0.1%만이 구매를 했다면 전부 구매를 하지 않았다고 예측할 경우 99.9%의 accuracy를 가짐 → 바람직하지 않음
⇒ accuracy가 낮더라도 실제 구매자를 잘 선택할 수 있는 모델이 있어야 바람직할 것
Precision
- 양성으로 예측된 값의 accuracy: 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
- precision = $\frac{\sum TruePositive}{\sum TruePositive + \sum FalsePositive}$
Recall
- Sensitivity
- 양성으로 예측하는 모델의 strength를 측정: 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
- recall = $\frac{\sum TruePositive}{\sum TruePositive + \sum FalseNegative}$
Specificity
- 음성으로 예측하는 모델의 능력을 측정: 실제 False인 것 중에서 모델이 False라고 예측한 것의 비율
- specificity = $\frac{\sum TrueNegative}{\sum TrueNegative + \sum FalsePositive}$
ROC Curve
recall과 specificity 간에는 trade-off 관계가 성립
→ “Receiver Operating Characteristics” Curve를 사용해 이 trade-off를 포착
: y축에 recall, x축에 specificity를 두어 그래프 시각화
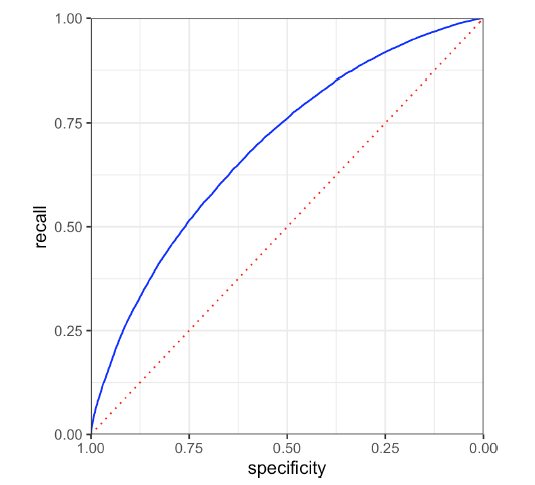
- 가운데 점선은 random 분류 결과
- 좌측 상단으로 그래프가 가까워질수록 좋은 classifier를 의미
AUC
ROC Curve는 분류의 성능을 측정하는 single measure가 아님 → 영역을 계산하면 되겠구나!
⇒ AUC 값이 클수록 좋은 classifier. 반대로 그 값이 0.5이면 그냥 random classifier 수준인 것

Lift
분류된 관측치에 대해 얼마나 예측이 잘 이루어졌는지 나타내기 위해 임의로 나눈 각 등급 별로 response, gain 등을 측정해 나타낸 도표
→ 예측이 잘 이뤄졌는지 확인 위해 랜덤 모델과 비교: 해당 모형을 사용하면 랜덤 모델에 비해 얼마나 이익(gain)을 볼 수 있는지 비율로 확인하는 것
- 데이터셋의 각 관측치에 대한 예측확률을 내림차순으로 정렬 (관측치: 2000개, pos: 400, neg: 1600 가정) → 관측치 1을 pos로 예측할 확률 99%, 관측치 7을 pos로 예측할 확률 97%, … 순으로 나열
- 데이터를 10개 구간으로 나눈 후 각 구간의 response 계산 → 각 구간의 관측치는 2000/10 = 200(개) → 각 구간의 실제로 pos인 비율 계산 → 구간 1(상위 10%)에서 실제 pos인 관측치가 150개: response = 150/200 *100 = 75, …
- 기본 향상도(실제 pos 비율)에 비해 response가 얼마나 높은지 확인: lift → 기본 향상도: 400 / 2000 *100 = 20 → 구간 1의 lift = 75 / 20 = 3.75, 구간 2의 lift, …, 구간 10(하위 10%)의 lift 계산
- 좋은 모델이라면 이 lift가 구간 1에서 구간 10으로 빠르게 감소해야 함





댓글 영역