결과가 우연 변동(chance variation) 범위를 벗어나면 통계적으로 유의(statistically significant)하다고 할 수 있다.
용어 정리
p-value
귀무가설(null hypothesis)이 맞다는 전제 하에, 표본에서 실제로 관측된 통계치와 '같거나 더 극단적인' 통계치가 관측될 확률 (여기서 말하는 확률은 '빈도주의' (frequentist) 확률이다)
0 - 1 사이의 값을 가지며 일반적으로 0.05 또는 0.01 등의 값을 기준으로 이보다 작을 경우 귀무가설을 기각한다.
Alpha
실제 결과가 통계적으로 유의하다고 간주되기 위해 우연한 결과가 초과해야 하는 "비정상성"의 확률 임계값
Type 1 error
귀무가설이 실제로 참이지만, 이에 불구하고 귀무가설을 기각하는 오류. 즉, 실제 음성인 것을 양성으로 판정하는 경우이다.거짓 양성또는알파 오류
Mistakenly concluding an effect is real (when it is due to chance)
Type 2 error
귀무가설이 실제로 거짓이지만, 이에 불구하고 귀무가설을 채택하는 오류. 즉, 실제 양성인 것을 음성으로 판정하는 경우이다.거짓 음성또는베타 오류
Mistakenly concluding an effect is due to chance (when it is real)
예시
price A는 price B에 비해 5% 더 잘 conversion 되며 이는 대규모 사업에서는 충분히 의미가 있다고 볼 수 있다.
0.8425% = 200/(23539+200)*100,
0.8057% = 182/(22406+182)*100
→ a difference of 0.0368 percentage points)
이 표에서는 총 45,000개 이상의 데이터를 활용하므로 빅데이터라고 간주할 수 있으며 여기서 통계적 유의성 테스트는 필요 없다. (통계적 유의성 테스트는 주로 소규모 샘플의 샘플링 변동성을 고려할 때 사용된다고 한다.)
하지만 conversion rates가 둘다 1% 미만이므로 실제 의미있는 값(conversion)은 몇 백대 미만이며 필요한 샘플 사이즈도 이러한 conversions에 의해 결정된다. Resampling 절차를 통해 price A와 price B의 conversion 차이가 우연 변동 범위 내에 있는지 테스트할 수 있다. 여기서 우연 변동(chance variation)이란 귀무가설(비율 사이에 차이가 없다)을 구체화하는 확률모델에 의해 생성되는 랜덤 변동(random variation)을 의미한다.
“If the two prices share the same conversion rate, could chance variation produce a difference as big as 5%?”
(두 가격이 같은 환산율을 공유하고 있는 경우, 우연의 변동에 의해 5%의 차이가 발생할 수 있는가)
p-Value
하지만 이렇게 단순히 그래프를 가지고 판단하는 것은 통계적 유의성을 측정하는 정확한 방법이라고 볼 수 없다. 따라서 수치적으로 표현되는 p-value가 더 중요하다. p-value는 귀무가설(null hypothesis)이 맞다는 전제 하에 확률 모형이 실제 관측 결과보다 같거나 큰 값을 생성하는 빈도수이므로 permutation test를 통해 관측된 값보다 같거나 큰 차이를 생성하는 비율을 계산해 p-value 값을 구할 수 있다.
mean(perm_diffs > obs_pct_diff)
[1] 0.308
np.mean([diff > obs_pct_diff for diff in perm_diffs])
계산을 해보면 p-vlaue 값을 0.308이 나오는 것을 볼 수 있는데 이는 약 30%의 확률로 실제 관측 결과보다 더 같거나 큰 혹은 극단적인 값을 얻게 된다는 것을 의미한다.
또한 이러한 문제에서 p-vlaue를 얻기 위해 반드시 permutation test를 이용해야 하는 것은 아니다. Binomial distribution을 알고 있다면 이를 이용해 p-value를 근사할 수 있다.
// x = 성공횟수, n = 시행횟수
> prop.test(x=c(200, 182), n=c(23739, 22588), alternative='greater')
2-sample test for equality of proportions with continuity correction
data: c(200, 182) out of c(23739, 22588)
X-squared = 0.14893, df = 1, p-value = 0.3498
alternative hypothesis: greater
95 percent confidence interval:
-0.001057439 1.000000000
sample estimates:
prop 1 prop 2
0.008424955 0.008057376
출력해보면 p-value 값이 0.3498이 나오는데 이는 앞에서 계산한 실제 p-value와 근사한 것을 알 수 있다.
Alpha
많은 통계학자들은 우연히 어떤 결과가 발생하기에 "너무 이상한"지 여부를 판단하는 것을 연구자의 재량에 맡기는 것에 대해 반대하며 오히려 "확률(귀무 가설) 결과의 5% 이상 극단 지점"과 같이 분계점(threshold)을 정해두는 것을 선호하는데 이때, 이 분계점을 alpha
라고 한다.
일반적으로 사용하는 alpha level은 5%와 1%이며 이 값들은 모두 임의로 선택한 값이다. 프로세스에 대해 올바른 결정을 x% 보증하는 방법은 없는데, 왜냐하면 확률 질문은 "우연히 이런 일이 일어났을 확률은?"가 아니라 "확률 모델(chance model)이 주어졌을 때, 이렇게 극단적인 결과가 나올 확률은?"이기 때문이다. 그런 다음 확률 모델의 적절성에 대해 역추론을 하지만, 이때의 판단은 확률을 수반하지 않아 지금까지 많은 혼란을 야기해 왔다.
p-value controversy
p-value의 사용에 관해서 많은 논쟁이 있었다. p-vlaue가 과연 분석에 도움이 되느냐에 대한 의문을 제기한 사람이 많았는데 대체적으로 p-value 사용의 가장 큰 문제점은 p-value가 실제로 무엇을 의미하는지 어렴풋이 알고 있는 연구자가 너무 많아 유의한 p-value를 얻는데 어려움을 격는다는 점과 많은 사람들이 p-value 사용시 실제 p-value가 갖는 의미보다 더 많은 의미를 원한다는 것이다.
일반적으로 사람들이 p-value로부터 얻어내고 싶은 것은 The probability that the result is due to chance. 인데 실제 p-value가 전하는 값은 The probability that, given a chance model, results as extreme as the observed results could occur. 이다.
이 차이는 미묘하지만 중요한데 significant p-vlaue는 무언가의 증명으로부터 얻어졌다고 보기 힘들다. 때문에 p-value의 실제 의미를 이해할 때 "statistically significant"의 결론에 대한 논리적 기초는 다소 약하다는 것을 알 수 있다.
Type 1 and Type 2 Errors
앞에서도 한 번 간단히 짚었지만 statistical significance를 판단할 때 두 가지의 오류가 발생할 수 있다.
Type 1 error
귀무가설이 실제로 참이지만, 이에 불구하고 귀무가설을 기각하는 오류. 즉, 실제 음성인 것을 양성으로 판정하는 경우이다.거짓 양성또는알파 오류
Mistakenly concluding an effect is real (when it is due to chance)
Type 2 error
귀무가설이 실제로 거짓이지만, 이에 불구하고 귀무가설을 채택하는 오류. 즉, 실제 양성인 것을 음성으로 판정하는 경우이다.거짓 음성또는베타 오류
Mistakenly concluding an effect is due to chance (when it is real)
사실 type 2 error는 오차라기보다는 표본 크기가 너무 작아서 효과를 탐지할 수 없는 경우이다. 이로 인해 p-value 값이 통계적 유의성(statistical significance)에 미달하는 경우(예: 5%를 초과), 실제로는 오류라기 보다는 "효과가 증명되지 않았음"을 의미한다. 이는 표본을 크게해 p-value를 작게 만들면 해결할 수 있다.
따라서 일반적으로 유의성 검정은(가설 검정이라고도 함) type 1 error를 최소화하는 방향으로 진행되며 기본적으로 random chance에 의해 속지 않도록 하는 것이다.
Data Science and p-Values
데이터 과학자가 하는 작업은 일반적으로 과학 저널에 발표되는 것이 아니기 때문에 p-vlaue의 가치에 대한 논쟁은 다소 학술적이라고 할 수 있다. 데이터 과학자가 실험을 진행할 때, p-vlaue 값은 흥미롭고 유용한 모형 결과가 정규 확률 변동 범위 내에 있는지 여부를 확인하려는 경우에 유용하다. 이때 p-vlaue 값은 의사결정 도구로서 지배적인 것이 아닌 단지 결정과 관련된 또 다른 정보로 간주되어야 한다.
예를 들어, p-value 값은 일부 통계 또는 기계 학습 모델에서 중간 입력으로 사용되는데, p-value 값에 따라 특정 feature를 모델에 포함할지의 여부를 결정할 수 있다.
t-Tests
유의성 검정 방법은 데이터가 카운트 데이터인지 측정 데이터인지, 또는 샘플의 수 및 측정 대상에 따라 여러 가지 유형이 있다. 매우 일반적인 t 검정법은 Student’s t-distribution에서 이름을 따온 것으로, W. S. Gosset이 단일 표본 평균(single sample mean)의 분포를 근사하기 위해 개발했다.
용어
Test statistic(검정 통계량)
차이 또는 관심있는 효과에 대한 측정법
t-statistic
평균과 같은 일반적인 검정 통계량의 표준화된 버전
t-distribution
관측된 t-통계량을 비교할 수 있는 기준 분포(이 경우 귀무가설에서 파생됨)
모든 유의성 검정의 경우 관심 있는 효과를 측정하고 관측된 효과가 정규 확률 변동(normal chance variation)의 범위 내에 있는지 여부를 확인하는 데 도움이 되는 검정 통계량을 지정해야 한다. Resampling test에서 데이터의 규모는 중요하지 않으며, 데이터 자체에서 기준(귀무가설) 분포를 생성하고 검정 통계량을 그대로 사용한다.
통계 가설 테스트가 개발되던 1920년대와 1930년대에는 데이터를 무작위로 수천 번 섞어서 resampling test를 하는 것이 가능하지 않았다. 통계학자들은 Gosset의 t-분포에 기초한 t-검정이 순열 검정에 대한 근사치라는 것을 발견했다. 이 방법은 데이터가 숫자 값으로 이루어진 매우 일반적인 두 샘플 비교(A/B 테스트)에 사용된다. 그러나 척도(scale)와 관계없이 t-분포를 사용하려면 표준화된 검정 통계량을 사용해야 한다.
// 대립 가설 : A페이지의 세션 시간 평균이 B페이지의 세션 시간 평균보다 작다
> t.test(Time ~ Page, data=session_times, alternative='less')
Welch Two Sample t-test
data: Time by Page
t = -1.0983, df = 27.693, p-value = 0.1408
alternative hypothesis: true difference in means is less than 0
95 percent confidence interval:
-Inf 19.59674 sample estimates:
mean in group Page A mean in group Page B
126.3333 162.0000
Resampling 모드에서는 데이터가 숫자인지 이진수인지, 표본 크기가 균형 있는지, 표본 분산인지 또는 다른 다양한 비틀림 현상들을 고려하지 않고 관찰된 데이터와 테스트할 가설을 반영하도록 솔루션을 구성한다. 공식 세계에서는 많은 변형들이 나타나는데, 통계학자는 이러한 변형들까지 탐색하고 학습해야 하지만, 데이터 과학자는 그렇지 않다. 일반적으로 데이터 과학자는 가설 테스트와 신뢰 구간의 세부 사항을 신경 쓰지 않는다.
Multiple testing
통계에는 "데이터를 충분히 고문하면, 데이터가 고백할 것이다."라는 말이 있다. 즉, 데이터를 충분히 다른 관점에서 보고 충분한 탐색을 하면 거의 항상 통계적으로 유의한 효과를 찾을 수 있다는 말이다.
예를 들어, 예측 변수가 20개이고 결과 변수가 하나이고 모두 랜덤하게 생성된 경우 alpha = 0.05 수준에서 20개의 유의성 검정을 연속적으로 수행하면 하나 이상의 예측 변수가 통계적으로 유의한 것으로 판명될 확률이 매우 높다. 앞에서 설명한 것처럼 이는 type 1 error다. 먼저 0.05 수준에서 유의하지 않은 검정 결과가 나올 확률을 찾아 이 확률을 계산할 수 있습니다. 유의하지 않은 테스트를 정확하게 수행할 확률은 0.95이므로, 20개 모두가 유의하지 않은 테스트를 정확하게 수행할 확률은 0.95 × 0.95 × 0.95... = 0.95^20 = 0.36 이다. 반대로 적어도 하나의 예측 변수가 유의하지 않은 테스트를 수행할 확률은 1 – (모든 변수가 유의하지 않을 확률) = 1 - 0.36 = 0.64이다. 이는 alpha inflation이라고 알려져 있다.
이 문제는 데이터 마이닝의 과적합 또는 "fitting the model to the noise" 문제와 관련이 있으며, 변수를 더 많이 추가하거나 모형을 더 많이 실행할수록 우연히 어떤 것이 "중요한" 것으로 나타날 확률이 높아지게 됨을 말한다.
False Discovery Rate
거짓 발견률이라는 용어는 원래 주어진 일련의 가설 검정이 유의한 효과를 잘못 식별하는 비율을 설명하기 위해 사용되었다. 즉 이는 다중비교문제에서 1종 오류를 조절하는 방법이다. 이는 유전자 배열 프로젝트의 일부로 엄청난 수의 통계 테스트가 수행될 수 있는 게놈 연구의 출현과 함께 특히 유용해졌다. 다중비교문제에서 기본적으로본페로니 방법을 많이 사용하는데 이는 전체 테스트의 1종 오류를 특정한 alpha 값 (예: 0.05)로 고정하는 방법이다. 즉, 전체 테스트가 유의하지 않은데 유의하다고 잘못판단할 확률을 0.05로 한다는 것이다.
Degrees of Freedom (자유도, d.f.)
자유도는 변동 가능한 값의 수를 나타내며 샘플 데이터에서 계산된 통계 정보에 적용된다. 예를 들어, 10개 값의 표본에 대한 평균을 알고 있는 경우 9의 자유도(표본 값 중 9개를 알고 나면 10번째 값을 계산할 수 있고 변동할 수 없음)를 가진다.
자유도는 많은 통계 테스트의 입력값으로 사용되며 분포의 모양에 영향을 미친다. 예를 들어, 분산 및 표준 편차에 대한 계산에서 볼 수 있는 분모에 위치한 n – 1 도 자유도에 해당한다. 특별히 n - 1을 사용하는 이유는 표본을 사용하여 모집단의 분산을 추정할 때 분모에 n을 사용하면 약간 아래쪽으로 치우친 추정치가 되기 때문이다. 분모에 n – 1을 사용하면 이러한 편향이 나타나지 않는다. 이처럼 기존 통계식에 사용하기 위해 샘플 통계를 표준화할 경우 표준화된 데이터가 적절한 기준 분포(t-분포, F-분포 등)와 일치하도록 하기 위해 자유도는 표준 계산의 일부로 사용된다.
그렇다면 자유도는 데이터 과학에서 중요한가?를 논해보면 적어도 유의성 테스트에서는 그렇게 중요하지 않다. 한 가지 예로, 공식적인 통계 테스트는 데이터 과학에서 극히 일부만 사용된다. 또 다른 예로 위에서 말한 모집단의 분산을 예로 들어보자면, 데이터 과학자들이 사용하는 데이터 사이즈는 일반적으로 거의 차이가 나지 않을 정도로 크기 때문에 분모가 n인지 n – 1인지가 그다지 중요하지 않다. 하지만 자유도를 반드시 고려해야 할 경우가 있는데 바로 회귀 분석(로지스틱 회귀 분석 포함)에서 요인 변수를 사용할 때이다. 요일(day of week)을 예측하는 경우를 생각해보면 요일은 7일이지만 요일을 지정할 수 있는 자유도는 6개 뿐이다. 예를 들어, 요일이 월요일부터 토요일까지가 아니라는 것을 알면 일요일이라는 것을 자동으로 알 수 있다. 따라서 월-토를 독립변수로 지정했을 때 일요일까지 독립변수로 포함시키게 되면 다중공선성으로 인해 회귀가 실패하게 된다.
질문 답변
◇ Q1 : t 분포를 사용하기 위해 표준화된 통계량을 사용한다는 것이 어떤 의미인가?
t-test는 목적에 따라 다음 두가지 경우에서 사용된다고 볼 수 있다. 1) 하나의 분포와 하나의 관측 데이터가 있을 때, 관측 데이터가 해당 분포에서 관찰될 수 있는 것인지 확인 2) 두 분포 A, B가 주어졌을 때, 두 분포간 유의미한 차이가 있는지 확인
첫번째 경우를 생각해보자. 만약 주어진 분포가 학생들의 키에 대한 분포이고 이때 키의 측정 단위가 m라고 할 때, 관측 데이터가 cm라면 t-test 검증 결과는 유의미하다고 나올 것이다. 단위 차이로 인해 두 값의 차이가 매우 크기 때문이다.
마찬가지로 두번째 경우도 생각해보면, 분포 A가 m기준이고 분포 B가 cm기준이라면 두 분포는 평균부터 이미 매우 다르게 나올 것이다. 따라서 t-test는 두 분포가 유의미하게 다르다고 판단할 것이다. 실제로 단위만 통일시키면 같은 분포인데 말이다!
결국 t-test는 데이터의 분포와 데이터 혹은 분포 간의 '비교'를 진행하는 작업이기 때문에 데이터 간의 scale에 대한 표준화가 반드시 이루어진 후 검증이 진행되어야 한다.
◇ Q2 : 2종 오류가 표본 크기가 너무 작아서 효과를 탐지할 수 없는 경우라는 것은 어떤 의미 인가?
귀무가설 검증에는 type 1,2 error가 존재한다. 한가지 주의할 점은 귀무가설 H0와 대립가설 H1이 있을 때, 우리가 실제로 맞는지 확인하고 싶은것은 H1이므로 H0가 reject되는 경우(즉, H1이 선택되는 경우)가 positive한 경우라는 것이다. 위의 표를 봐도 판단 결과가 reject일 때를 positive로 둔다는 것을 알 수 있다.
Type 1 error는 실제로 H0가 맞는데 reject 해버린 경우로, 비교 대상의 두 분표(혹은 데이터)가 같은데 다르다고 판단하는 경우이다. 두 분포가 실제로 같은데 다르다고 판단하는 것은 명백히 잘못 판단하는 것에 속한다.
하지만 Type 2 error는경우가 좀 다르다. Type 2 error는 실제로는 H1이 맞는데 reject하지 못한 경우로, 비교 대상의 두 분포(혹은 데이터)가 다른데도 같다고 판단하는 경우이다. 두 분포가 실제로 다른데 샘플링을 너무 조금만 해서 실제 분포와 다르게 그려졌다면 t-test에서 같다고 판단할 수 있다. 이는 두 분포가 실제로 다르다면 데이터를 추가해 줌으로써 해결할 수 있는 문제이다. 데이터를 추가해주게 되면 샘플링을 가지고 그린 두 분포의 그래프는 점점 뚜렷한 차이를 보이기 때문이다.
이 말이 잘 이해가 가지 않을 수 있는데 이는 t-test의 식이 나온 과정을 생각해보면 좀 더 명확하게 알 수 있다.
고려대학교 데이터 과학 수업 자료 중 일부 발췌
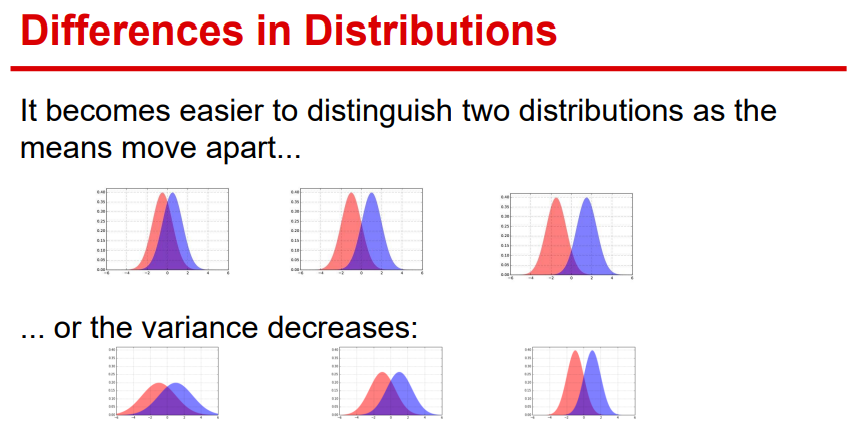
t-test가 하고 싶은 것은 두 분포에 실제로 차이가 있느냐?를 검정하는 것이다. 그렇다면 두 분포는 언제 차이가 크다고 말할 수 있을지 생각해보면 두 분포간 평군의 차이가 크거나 두 분포의 분산이 작은 경우이다. 평균의 차이가 크면 분포가 다르다는 것은 상식적으로 이해가 잘 되지만 분산이 작으면 왜 차이가 큰지는 이해가 안 될 수 있다. 위 그림에서 아래의 세 그래프를 보면 평균이 일정한 상태일 때, 분산이 작아질 수록 두 분포의 그래프끼리 겹치는 면적이 적어지는 것을 볼 수 있으며 이는 두 분포의 차이가 커짐을 의미한다.
t-test의 식은 이를 단순히 수식화 한 것인데
분자에 평균의 차가 있고 분모에는 두 분포의 분산이 들어있는 것을 볼 수 있다. 여기서 n1, n2는 샘플의 수인데 샘플이 많아지면 분산이 작아지는 것은 아마 다들 알고 있을 것이라 생각한다. 때문에 결국 정리하면 1. 평균의 차이가 클수록 2. 분산이 작을수록 3. 샘플 수가 많을수록 t 값은 커지는 것을 알 수 있다.
정리하면 type 2 error는 두 분포가 다른데 같다고 판단한 것이고 그 말은 t 값이 크게 나와야 하는데 작게 나왔다는 것이므로 t 값을 키우기 위해 n 값 (샘플 수)를 키우면 해결할 수 있다는 것이다.
◇ Q3 : 본페로니 방법은 무엇인가?
T-test에서 alpha = 0.05 를 사용한다는 것의 의미는 귀무가설 H0를 판단할 때, 5%의 판단 오차는 감수 하겠다는 의미이다. 그런데 검정하고 싶은 가설이 한 개가 아니라 2개이고 (H0, H0') 이때 마찬가지로 alpha = 0.05를 사용한다고 생각해보자. 이 경우, 둘 중 하나가 기각되게 되면 결국 전체가 기각되게 된다. 그렇다면 이때도 alpha = 0.05를 썼기 때문에 내가 감수하는 오차가 5%라고 말할 수 있는가? 라고 물으면 아니라는 것이다. H0에서 감수되는 오차와 H0'에서 감수되는 오차가 각각 5%인 것이기 때문에 내가 전체적으로 감수해야 할 오차는 5%보다 커진다.
따라서 가설 검증에서 가설을 여러 개 이용할 경우, 가설을 하나만 사용할 때보다 alpha 값을 더 타이트하게 좁혀줘야만 내가 감수해야 하는 오차가 작아지게 된다. 본페로니 방법은 이를 해결하기 위해 alpha를 조정하는 과정으로 n개의 가설을 기존의 alpha 정도의 오차로 검증하고 싶은 경우 new alpha = alpha/n 을 이용하면 된다.











댓글 영역